What is Scholarly HTML?
Abstract
Scholarly HTML is a domain-specific data format built entirely on open standards that enables the interoperable exchange of scholarly articles in a manner that is compatible with off-the-shelf browsers. This document describes how Scholarly HTML works and how it is encoded as a document. It is, itself, written in Scholarly HTML.
Motivation
Scholarly articles are still primarily encoded as unstructured graphics formats in which most of the information initially created by research, or even just in the text, is lost. This was an acceptable, if deplorable, condition when viable alternatives did not seem possible, but document technology has today reached a level of maturity and universality that makes this situation no longer tenable. Information cannot be disseminated if it is destroyed before even having left its creator’s laptop.
According to the New York Times, adding structured information to their recipes (instead of exposing simply as plain text) improved their discoverability to the point of producing an immediate rise of 52 percent in traffic (NYT, 2014). At this point in time, cupcake recipes are reaping greater benefits from modern data format practices than the whole scientific endeavour.
This is not solely a loss for the high principles of knowledge sharing in science, it also has very immediate pragmatic consequences. Any tool, any service that tries to integrate with scholarly publishing has to spend the brunt of its complexity (or budget) extracting data the author would have willingly shared out of antiquated formats. This places stringent limits on the improvement of the scholarly toolbox, on the discoverability of scientific knowledge, and particularly on processes of meta-analysis.
To address these issues, we have followed an approach rooted in established best practices for the reuse of open, standard formats. The «HTML Vernacular» body of practice provides guidelines for the creation of domain-specific data formats that make use of HTML’s inherent extensibility (Science.AI, 2015b). Using the vernacular foundation overlaid with «schema.org» metadata we have produced a format for the interchange of scholarly articles built on open standards, ready for all to use.
Our high-level goals were:
- Uncompromisingly enabling structured metadata, accessibility, and internationalisation.
- Pragmatically working in Web browsers, even if it occasionally incurs some markup overhead.
- Powerfully customisable for inclusion in arbitrary Web sites, while remaining easy to process and interoperable.
- Entirely built on top of open, royalty-free standards.
- Long-term viability as a data format.
Additionally, in view of the specific problem we addressed, in the creation of this vernacular we have favoured the reliability of interchange over ease of authoring; but have nevertheless attempted to cater to the latter as much as possible. A decent boilerplate template file can certainly make authoring relatively simple, but not as radically simple as it can be. For such use cases, Scholarly HTML provides a great output target and overview of the data model required to support scholarly publishing at the document level.
An example of an authoring format that was designed to target Scholarly HTML as an output is the DOCX Standard Scientific Style which enables authors who are comfortable with Microsoft Word to author documents that have a direct upgrade path to semantic, standard content.
Where semantic modelling is concerned, our approach is to stick as much as possible to schema.org. Beyond the obvious advantages there are in reusing a vocabulary that is supported by all the major search engines and is actively being developed towards enabling a shared understanding of many useful concepts, it also provides a protection against «ontological drift» whereby a new vocabulary is defined by a small group with insufficient input from a broader community of practice. A language that solely a single participant understands is of limited value.
In a small, circumscribed number of cases we have had to depart from
schema.org, using the https://ns.science.ai/
(prefixed with sa:) vocabulary instead
(Science.AI, 2015a). Our goal is
to work with schema.org in order to extend their
vocabulary, and we will align our usage with the outcome of these discussions.
Definition
A Scholarly HTML document is a valid HTML document that follows some additional rules to specialise its meaning and make it predictable to processors wishing to produce or consume scholarly articles. These rules are outlined in the following sections.
Please note that in its current state this specification is often informal in the manner in which it describes its constraints. This is to facilitate review by people unfamiliar with formal specification writing. As the format solidifies, it will be made more formal progressively (but attempt to remain readable).
File & Supporting Structure
The document must be encoded in UTF-8, and transmitted with a media type of
text/html. It must feature a DOCTYPE as its preamble.
The html root element must feature a valid lang attribute.
The head element of the document must contain a
<meta charset="utf-8"> element (preferable as its
first child), a
<meta name="viewport" content="width=device-width">
element (and no other viewport meta), and a title element. All
the other content of the head is ignored.
The body element must have a prefix attribute, which must
declare the following mapping:
| Prefix | URL |
|---|---|
| schema | http://schema.org/ |
| xsd | http://www.w3.org/2001/XMLSchema# |
| sa | https://ns.science.ai/ |
Having to declare prefixes is undoubtably an annoyance and it does hurt the human
authorability of the format (since hand-creating a document essentially requires a
boilerplate prefix declaration). This trade-off is made for several reasons. The most
important motivation is that having predictable prefixes means that the content can be
styled with CSS using reliable attribute selectors on the semantic information that
describes the document’s structure. The alternative would be to use URLs everywhere,
such that instead of sa:Abstract we would have
https://ns.science.ai/Abstract; but in practice that approach is more
painful since the content then becomes bloated with URLs that are longer than is
comfortable.
The RDFa content of the article must systematically make use of these prefixes when the
values match their URLs as prefixes. Authors may declare other prefix-URL mappings in
the prefix attribute of the body element (or
prefix attributes elsewhere), including other prefixes mapping to the same
URLs if needed, but inside of the article’s content these prefixes must be used for
these URLs.
Article Structure
The article content is everything that is contained inside the first
article element in document order that has a
typeof="schema:ScholarlyArticle". Everything part of the body
outside of that subtree is ignored. This enables publishers to surround the article
content with any amount of supporting markup, for instance for headers, footers,
or navigation, as well as to wrap the article inside arbitrary markup that may be
needed for stylistic reasons.
The article element should have
a resource attribute, usually with a value
of #. The reason for that is to grant it a
URL that can be targeted by other properties. The
resource attribute can take any value, but it
must then be matched by the
about attributes of the properties targeting
it. If resource is omitted, the only way in
which those properties can target it is by knowing the URL
from which the document was retrieved.
The first element child of the article element must be an h1
heading that serves as the primary title for the document. It may itself contain markup.
The white-space-normalised text value of the h1 must appear as a substring
of the white-space-normalised text value of the title element. This ensures
semantic alignment between the two, while enabling publishers to add their name to the
title so as to identify themselves there alongside the content.
Any children of article that are not section elements are
ignored.
The first section child element of the article must be the
Authors and Affiliations section. It has no typeof
and its specific rules are outlined in its own chapter below.
The section elements can be nested arbitrarily deep. Each
section element must have as its first element child an hX
heading element the numeric part of which must be the number of section
ancestor elements that heading elements has up to the article element, plus
one. If the numeric part is greater than 6, then h6 must be used but an
aria-level attribute must be added that reflects the accurate depth.
(The aria-level attribute can be used at lower depths but is not required
there.)
Each section element may contain an arbitrary number of
hunk elements, followed by an arbitrary number of
section elements being subsections. Note that
hunk elements must imperatively appear before the
subsections.
Sections are expected to be typed using the typeof attribute. The following
typeof values are currently understood:
sa:Funding(which has its specific structure)sa:Abstractsa:MaterialsAndMethodssa:Resultssa:Conclusionsa:Acknowledgementssa:ReferenceList
Hopefully these types are largely self-documenting, they are described further in the Scholarly Article ontology (Science.AI, 2015a).
The section typed sa:ReferenceList has special processing rules described
in the References section.
Hunk Elements
Hunk elements are the meaningful blocks from which sections are built. They contain text and inline elements. There are several types of hunk elements.
The most common hunk element is p, which is used to capture paragraphs. It
requires no special processing.
The blockquote, ul, ol, and dl
elements can be used as they typically would and require no special treatment.
The aside hunk element is used to capture text boxes. If it contains an
hX heading element, that element must be its first element child and its
numeric part must reflect its depth, making use of aria-level according to
the same rules as apply for section. The other children of
aside must all be hunk elements.
The figure element is a general container for content units that are
embedded inside the main body of the text. It can come in several flavours that are
dictated by its typeof attribute.
If figure has typeof="sa:Image" then it is an image container.
It must contain an img child element and should contain a
figcaption labelling that image. An example of an image figure would be:
If figure has typeof="sa:Table" then it is a table container.
It must contain nothing other than a table element. If a caption is
available, it should be included using the caption child element of the
table, and not the figcaption child of the
figure.
If figure has typeof="sa:Formula" then it is a formula
container. It must contain a math element and optionally a
figcaption describing the formula. The math element must be
valid MathML 3. Additionally, given the dismal state of support for MathML in Web
browser the math element must contain an annotation
descendant with the TeX equivalent of the formula.
If figure has typeof="schema:SoftwareSourceCode"
then it is a code container. It must contain a pre element
and optionally a figcaption. The pre element must contain as
its only child a code element.
If you wish to specify the type of the language used in the code, the
figure needs to have a schema:programmingLanguage property
containing a type schema:Language, itself with a schema:name
containing the the lowercase name of one of the languages from the
list
of programming languages. Canonically, this would look like the following source:
<figure typeof="schema:SoftwareSourceCode">
<pre property="schema:programmingLanguage" typeof="schema:Language">
<meta property="schema:name" content="python">
<code>import foo</code>
</pre>
<figcaption>
How to import foo.
</figcaption>
</figure>
Inline Elements
Inline elements essentially decorate, describe, and enrich text. Inside of
hunk elements, of heading elements, and of captioning
elements (caption and figcaption) the following inline
elements can be used (and where applicable they can nest within one another):
aabbrbdibdocitecodedatadeldfnemimg(for small, contextual images that should not be figures)inskbdmarkmath(for inline equations that should not be figures; they must also contain a TeX annotation)meterqruby(with embeddedrb,rt,rtc, andrp)sampspanstrongsubsupsvg(for small, contextual images that should not be figures)timevarwbr
If an a element is linking to a citation, then it must have
property="schema:citation"; if it is linking
to a figure or another creative work, it must
have property="schema:hasPart"
or property="schema:isBasedOnUrl". These are
known as flavoured links, they can be used to
enhance the user experience by treating their behaviour
differently from regular links.
The References Section
The references section is a special type of section element with
typeof="sa:ReferenceList".
Apart from its heading element, it must contain nothing other than an ol
or a dl element.
If using a dl element, its content must be exclusively a strictly
alternating sequence of dt then dd elements, with the latter
being the citation-bearing element. The dt is used as a label in some
citation formats.
If using an ol, then its content is only li elements that are
the citation-bearing elements.
The citation-bearing element will have an id and be
schema:Book for books or
typeof="schema:ScholarlyArticle" (or its subclass
schema:MedicalScholarlyArticle, with probably more to come). Its
content follows the «flexcite» format (being defined as part of this document, see
#4). The
references section of this document is an example.
<li id="ref-something" typeof="schema:ScholarlyArticle"
resource="http://dx.doi.org/10.1000/182">
<span property="schema:author" typeof="schema:Person">
<span property="schema:familyName">Jones</span>
<span property="schema:givenName">K</span><span
property="schema:additionalName">E</span>
</span>,
<span property="schema:author" typeof="schema:Person">
<span property="schema:familyName">Patel</span>
<span property="schema:givenName">N</span>
</span>.
<cite property="schema:name">Global trends in emerging infectious diseases.</cite>
<span property="schema:isPartOf" typeof="schema:PublicationVolume">
<span property="schema:isPartOf" typeof="schema:Periodical">
<span property="schema:name">Nature.</span>
</span>
<time about="http://dx.doi.org/10.1000/182" property="schema:datePublished"
datetime="2008-01" datatype="xsd:gYearMonth">2008 Jan</time>;
<span property="schema:volumeNumber">451</span>
</span>:<span property="schema:pageStart">990</span>-<span
property="schema:pageEnd">4</span>
</li>
At the semantics level, a citation is a schema:ScholarlyArticle (or subtype)
with an id to reference it internally in the document and a
resource that is a URL identifying it (its DOI for instance, preferable in
HTTP-retrievable form).
That schema:ScholarlyArticle has any number of schema:author
which are schema:Person (with the usual schema:givenName,
schema:familyName, etc.). A child cite element, with
property="schema:name" (and optionally a link child) provides the title
of the article.
The publisher is described using a nested schema:isPartOf structure of
schema:PublicationIssue, schema:PublicationVolume,
and schema:Periodical (with only those that are known being used). Both
schema:volumeNumber and schema:issueNumber may be used on the
volume and issue.
A time element with property="schema:datePublished" provides
the publication date, which is expressed in text in human-readable form and in the
datetime attribute in standard form. A datatype attribute
matching the date format must be provided.
Both schema:pageStart and schema:pageEnd may be provided.
Beyond the semantics, a more specific serialisation known a «Flexcite» is in the works and will be added here soon. Its properties are simple: when unstyled it reads linearly in a human-friendly manner (so as to be accessible), and it can be styled with CSS to be turned into arbitrary citation style preferences.
The Authors & Affiliations Section
Capturing authors, the affiliations and their relationship to the article is the most intricate part of Scholarly HTML. Care was taken to avoid repetition and to keep the markup density as reasonable as possible, but the data to content ratio remains relatively high.
It is probably best to start from an example and then to explain it:
<!-- The author and contributor list -->
<article resource="#">
…
<section>
<ol>
<!-- The first author, Robin Berjon -->
<li property="schema:author" typeof="sa:ContributorRole">
<a property="schema:author" href="http://berjon.com/" typeof="schema:Person">
<span property="schema:givenName">Robin</span>
<span property="schema:familyName">Berjon</span>
</a>
<a href="#scienceai" property="sa:roleAffiliation" resource="http://science.ai/">a</a>
<sup property="sa:roleContactPoint" typeof="schema:ContactPoint">
<a property="schema:email" href="mailto:robin@berjon.com" title="corresponding author">✉</a>
</sup>
</li>
<!-- A contributor, Sebastien Ballesteros -->
<li property="schema:contributor" typeof="sa:ContributorRole">
<a property="schema:contributor" href="https://github.com/sballesteros" typeof="schema:Person">
<span property="schema:givenName">Sebastien</span>
<span property="schema:familyName">Ballesteros</span>
</a>
<a href="#scienceai" property="sa:roleAffiliation" resource="http://science.ai/">a</a>
</li>
</ol>
<!-- The affiliation list -->
<ol>
<li id="scienceai">
<a href="http://science.ai/" typeof="schema:Corporation">
<span property="schema:name">science.ai</span>
</a>
</li>
</ol>
</section>
…
</article>
The markup is relatively convoluted, but the data model is rich:
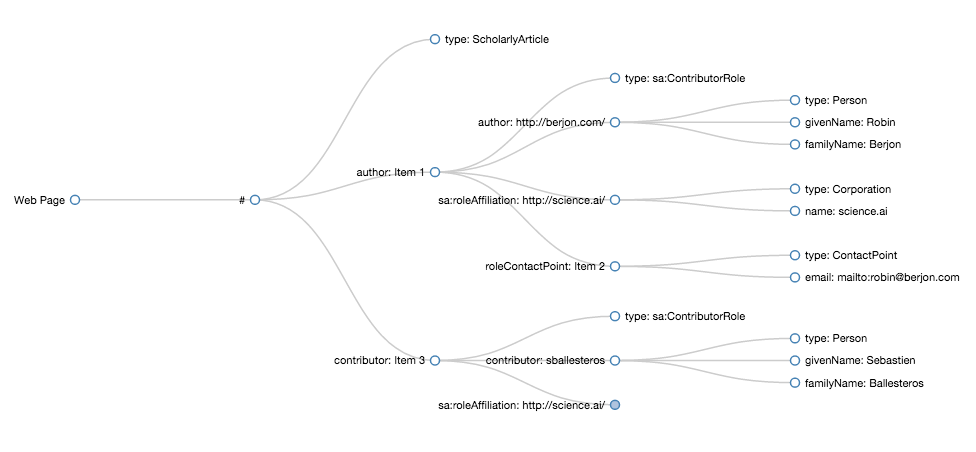
This section has no typeof and
no heading element. It contains a first ol
which lists authors, and optionally a
second ol to list affiliations.
Each li in the authors ol has
property="schema:author" or property="schema:contributor" and a
typeof="sa:ContributorRole".
A sa:ContributorRole type (following the
semantic of
schema.org Role) is
used so that affiliations or contact informations (email
address, etc.) relevant to this specific scholarly article
(and this specific scholarly article only) can be
specified. This is important as authors may have different
affiliations and contact points at the time they are
publishing a scholarly article but may want to specify
only a subset of those. Readers not familiar with the
semantic of schema.org Role can consult
the introductory
blog post.
Inside of that li, arbitrary properties
of schema:Person, filling
the schema:author property of
the sa:ContributorRole can be specified, but
providing at least schema:givenName and
schema:familyName. It is recommended that
these properties are wrapped into an hyperlink
identifying the person with a URL to their home page,
their ORCID, or an email
address.
If there is an affiliations ol and a given
author is affiliated, there must be an a
element with its href pointing to that
affiliation, a resource matching the URL
identifying the affiliation,
and property="schema:roleAffiliation". The
content of that a element must be a string
that matches the one that will be generated by CSS to
label the affiliation; Latin lowercase being
recommended. (This is a hack, but we can only do so much
within the limits of CSS — better counter
would be needed.)
If an author (or contributor) is a corresponding author, a
last sup element needs to be added to
its li
with property="sa:roleContactPoint", typeof="schema:ContactPoint"
(or subclass). Inside the sup element, there
must be at least a link to the contributor email address
(mailto:). More contact information such as
properties of schema:PostalAddress may be
added using meta tags.
If there is an affiliations ol, each li in it must have an
id which the authors link to. In turn it contains an a
element linking to the affiliation with typeof set to either
schema:Organization or one of its
subtypes. Inside the a needs to sit a span (or any
acceptable element, really) with property="schema:name", containing the
name.
The Funding Section
The funding information attached to an article involves a list of sponsors each of which offers a list of funding sources. Again, an example probably makes the idea clearer:
<article resource="#">
<!-- This work was sponsored by the Child Detection Agency (CDA) under the grant grantId -->
<section typeof="sa:Funding">
<h2>Funding</h2>
<p about="#" rel="schema:sponsor">
<span typeof="sa:SponsorRole">
This work was sponsored by the
<a
property="schema:sponsor"
href="http://pixar.wikia.com/wiki/CDA"
typeof="schema:Organization"
>
<span property="schema:name">Child Detection Agency</span>
(<span property="schema:alternateName">CDA</span>)
</a> under the grant
<a
property="sa:roleOffer"
typeof="sa:FundingSource"
href="http://pixar.wikia.com/wiki/CDA#grantId"
>
<span property="schema:serialNumber">grantId</span>
</a>
</span>
</p>
</section>
</article>
The section has typeof="sa:Funding" and an arbitrary heading title, like
other sections.
It contains a series of hunks that are
rel="schema:sponsor" (there can also be other content, it is ignored for
our purposes). The example above uses a p and a narrative style for its
content, but you have freedom to use other encodings.
As for contributor affiliations, source of fundings are
expressed using a subclass of schema:Role (sa:SponsorRole).
The usage of schema.org Role type is needed
to describe the source of fundings specific to a scholarly
article as opposed to all the source of funding of an
organization (relevant or not to our scholarly article of
interest).
The funder will be typeof="schema:Organization" (or a subtype thereof), as the object of a
schema:sponsor property on the sa:SponsorRole. It
will be identified through its URL (as in the a above), and will typically
have schema:name and often schema:alternateName.
The specific source of funding is of type sa:FundingSource, as the object of a
sa:roleOffer property on the sa:SponsorRole. It
should have a URL identifying it and a schema:serialNumber that is its
labeled identity.
Data rich scholarly articles
Scholarly Articles are often part of a larger network of creative works containing dataset, code, additional figures, tables or media (audio, video). Even within a scholarly article, some creative works can be encoded in different ways (for instance, figures typically comes in different resolutions). Scholarly HTML aims to formally describe (and help archive) this larger context.
Further data about a scholarly graph can be exposed within the article in RDFa or as JSON-LD islands. When JSON-LD is used, it is recommended not to duplicate the data already serialized in RDFa. JSON-LD should be reserved to expose data not directly present in the HTML markup.
{
"@context": "http://schema.org",
"@id": "http://example.com/graph",
"@graph": [
{
"@id": "http://example.com/article",
"@type": "ScholarlyArticle",
"isPartOf": "http://example.com/graph",
"isBasedOnUrl": ["http://example.com/code"],
"hasPart": {
"@id": "http://example.com/image",
"@type": "Image",
"encoding": [
{
"@id": "http://example.com/encodingsmall",
"@type": "ImageObject",
"contentUrl": "http://example.com/small"
"height": "400px",
"width": "400px",
"isBasedOnUrl": ["http://example.com/encodinglarge"]
},
{
"@id": "http://example.com/encodinglarge",
"@type": "ImageObject",
"contentUrl": "http://example.com/large",
"height": "1200px",
"width": "1200px"
}
]
}
},
{
"@id": "http://example.com/code",
"@type": "SoftwareSourceCode",
"codeRepository": "http://example.com/repository",
"isPartOf": "http://example.com/graph"
}
]
}
A scholarly graph, detailing the context of a
scholarly article in JSON-LD. Here, the scholarly
article contains a figure available in 2 sizes and is
based on software source code available in a code
repository. The schemaIsBasedOnUrl
property also indicates that the small image was
derived from the large one.
A scholarly graph provides a manifest for a scholarly
article listing all the creative works, their encodings
and the relationship between these objects (expressed
with schema:hasPart
and schema:isBasedOnUrl).
| Creative Work | Property | Encoding |
schema:ScholarlyArticle |
schema:encoding |
sa:DocumentObject |
sa:Image |
schema:encoding |
schema:ImageObject |
sa:Audio |
schema:encoding |
schema:AudioObject |
sa:Video |
schema:encoding |
schema:VideoObject |
schema:Dataset |
schema:distribution |
schema:DataDownload |
schema:Table |
schema:encoding |
sa:TableObject |
schema:SoftwareSourceCode |
schema:encoding |
schema:MediaObject |
Semantic context of a scholarly article
Scholarly Articles (and their associated resources) are
frequently tagged to improve their discoverability. For
instance,
the National
Library of Medicine uses
the Medical
Subject Headings (MeSH) controlled vocabulary to index
journal articles in the life sciences. Scholarly HTML
leverages schema.org and the schema:about
property to efficiently expose this information to search
engines. When possible,
schema.org MedicalEntity
(and subclasses) should be used to describe biomedical
concepts.
{
"@context": "http://schema.org",
"@id": "http://example.com/article",
"@type": "ScholarlyArticle",
"about": {
"@id": "http://id.nlm.nih.gov/mesh/D007251",
"@type": "InfectiousDisease",
"name": "Influenza, Human",
"description": "An acute viral infection in humans involving the respiratory tract. It is marked by inflammation of the NASAL MUCOSA; the PHARYNX; and conjunctiva, and by headache and severe, often generalized, myalgia.",
"code": {
"@type": "MedicalCode",
"codeValue": "D007251",
"codingSystem": "MeSH"
},
"mainEntityOfPage": {
"@id": "#Discussion",
}
}
}
schema:about property to
expose concepts about a scholarly article. Note that
the schema:mainEntityOfPage property is
used to specify the part of the article where the
concept is relevant.
Hypermedia controls
A Scholarly Article (or any resource part of a scholarly graph) can be made actionable with the addition of hypermedia controls provided through schema.org actions. Readers not familiar with schema.org Actions should refer to the actions overview document for a quick introduction.
{
"@context": "http://schema.org",
"@id": "http://example.com/article",
"@type": "ScholarlyArticle",
"potentialAction": {
"@type": "ReviewAction",
"agent-input": {
"@type": "PropertyValueSpecification",
"valueRequired": true
},
"resultReview-input": {
"@type": "PropertyValueSpecification",
"valueRequired": true
},
"target": {
"@type": "EntryPoint",
"httpMethod": "PUT",
"urlTemplate": "http://example.com/review"
}
}
}
Acknowledgements
Scholarly HTML would like to thank Scholarly HTML (you read that right) for blazing the trail perhaps a few years too soon. Particularly, the following people were particularly kind and helpful: Peter Sefton, Richard Smith-Unna, and Peter Murray-Rust.
PLOS has a short history of Scholarly HTML that is worth reading (and would be worth updating).
Dan Brickley was kind enough to drop by the office to chat about our usage of schema.org even though he was tired and hungry. As always, examples involving fish tanks are the most helpful. Tzviya Siegman and Dave Cramer have shared ideas that we happily stole.
Patrick Johnston's input has been crucial, notably in modelling authoring. We can only hope that getting those details exactly right have not caused him to lose too much sleep.
We also received very useful feedback and pointers from: Kjetil Kjernsmo (DAHUT!), Silvio Peroni, Justin Johansson, Alf Eaton, Raniere Silvia, and Mike Smith.
If we somehow forgot you in this list and you are too gracious to complain, we love you all the same.
Conclusion
Scholarly HTML is currently a work in progress and is open to change. If you have feedback, simply open an issue on GitHub, or make a pull request.
We believe that this vernacular establishes that it is possible to capture scholarly information accurately, while retaining a clean HTML structure that does minimum violence to the language’s spirit.
The science.ai platform currently supports (most of) Scholarly HTML, but our goal is not to make this a proprietary standard — quite the opposite. We would like the scholarly publishing as much as possible to align with common practices so that we can all focus on problems more interesting than content conversion.
References
- NYT, 2014
- The Full New York Times Innovation Report, by New York Times ; .
- Science.AI, 2015a
- The Scholarly Article ontology, by Science.AI ; .
- Science.AI, 2015b
- Vernacular — HTML Made Special, by Science.AI ; .